11.2 Sampling Distributions of PRE and F
Just as finding a difference between the two means (e.g., $6.05) does not by itself rule out the possibility that the true difference in the DGP could be 0, the same is true of PRE. The two-group model of Tip reduces error by .07 in the data. But that doesn’t rule out the possibility that the true PRE in the DGP might be 0.
If there is no difference between the groups in the DGP, then none of the error from the empty model would be reduced by the two group model that includes Condition. That is if \(\beta_1=0\), then the true value of PRE in the DGP would also be 0. One follows from the other.
Even if the true PRE in the DGP is 0, the PRE calculated by fitting a model to a sample of data would not necessarily be 0. It would vary due to random sampling variation. As before, the question of how much it might vary is one we can answer by constructing a sampling distribution of PRE based on the empty model.
If the sample PRE falls in the unlikely region, we would probably decide to reject the empty model and to adopt the complex model. But if the sample PRE falls in the not unlikely .95 region of the sampling distribution, we might decide to not reject the empty model, as the data we collected would be judged consistent with a DGP in which PRE is 0.
It is important to note that the question we are asking using the sampling distribution of PRE is the same one we asked using the sampling distribution of \(b_1\): in both cases we want to know how likely it is that the sample statistic we observed could have been generated just by chance assuming that the empty model is true.
Saying “the true PRE = 0” is just one more way to refer to the empty model of the DGP. It’s the same as saying that there is no effect of smiley face, or that \(\beta_1=0\). Using the sampling distribution of PRE should, therefore, lead to similar results as using the sampling distribution of \(b_1\). Let’s construct a sampling distribution and find out if it does!
Constructing a Sampling Distribution of PRE
Let’s bring back a picture from the prior chapter to remind us how we used shuffle() to generate a sampling distribution of \(b_1\) assuming \(\beta_1=0\). By showing us the distribution of possible \(b_1\)s that the empty model of the DGP could have produced, the sampling distribution provided a context within which we could interpret the observed mean difference between the smiley face and no smiley face conditions ($6.05).
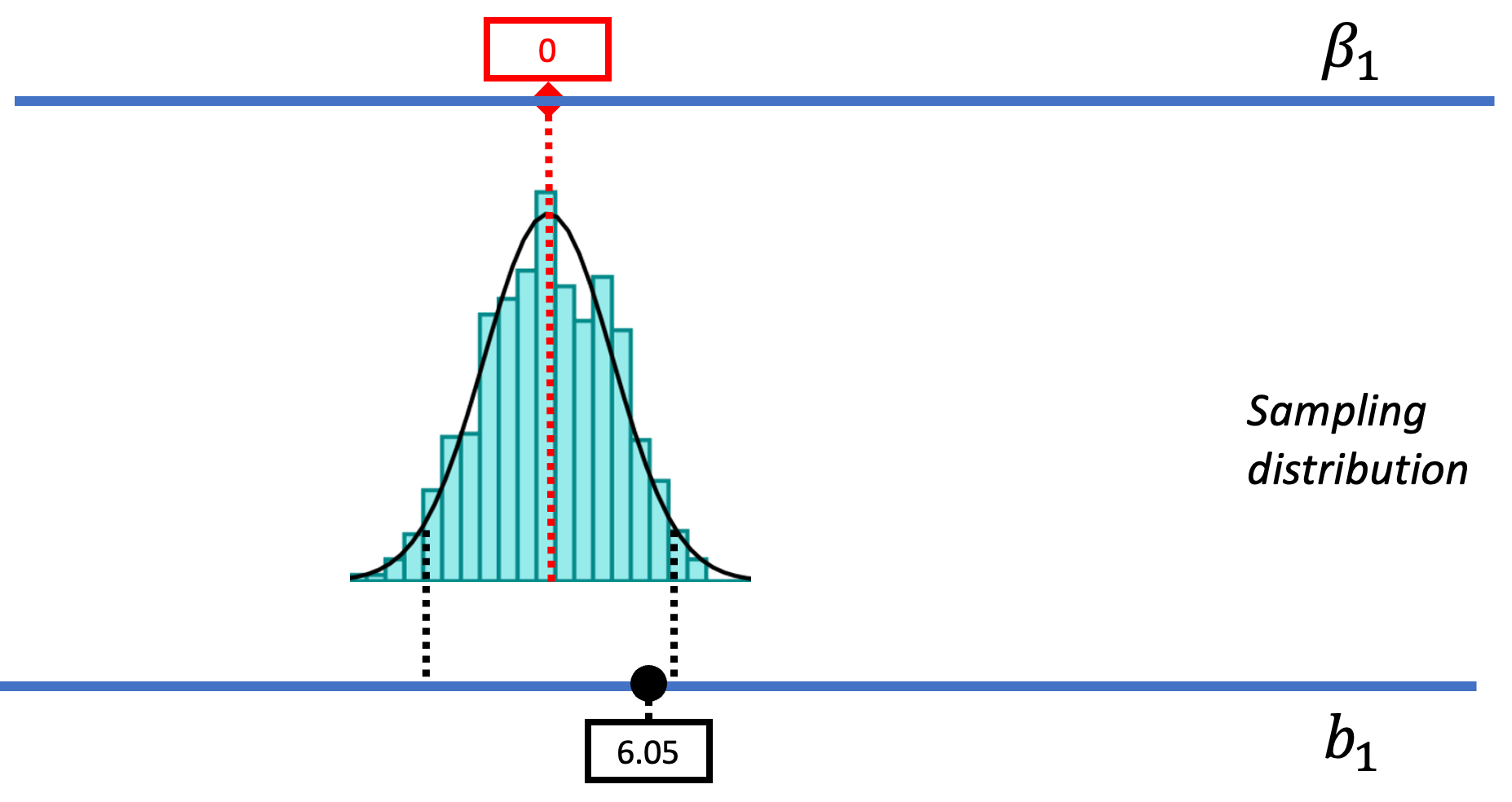
We can use the same approach to creating the sampling distribution of PRE. We will start by using shuffle() to randomize the relationship between Condition and Tip, then, instead of calculating \(b_1\), we will calculate PRE for the shuffled sample. By using shuffle() we are simulating a world where the empty model is true and where each table would have tipped the same amount regardless of which condition it was assigned to.
The line of R code below will (1) shuffle the values of Tip, (2) create a model of the shuffled Tip using Condition as the explanatory variable, and then (3) calculate the PRE of the model. It does all this for a single shuffled (or randomized) set of data.
PRE(shuffle(Tip) ~ Condition, data = TipExperiment) Modify the code in the window below to generate 10 shuffled PREs.
require(coursekata)
# modify the code in the window below to generate 10 shuffled PREs
PRE(shuffle(Tip) ~ Condition, data = TipExperiment)
do(10) * PRE(shuffle(Tip) ~ Condition, data = TipExperiment)
ex() %>% {
check_function(., "do") %>%
check_arg("object") %>%
check_equal()
check_operator(., "*")
check_function(., "PRE") %>% {
check_arg(., 1) %>% check_equal()
check_arg(., 2) %>% check_equal()
}
} PRE
1 0.1122759121
2 0.0014887642
3 0.0062726047
4 0.0284102391
5 0.0056457566
6 0.0006969561
7 0.0545399059
8 0.0404193284
9 0.0356684799
10 0.0034682844We can see that the purely random DGP in which there is no effect of smiley face on Tip produces a variety of PREs.
Let’s extend the code above to create a sampling distribution of 1000 PREs, save them into a new data frame that we will call sdoPRE (for sampling distribution of PRE), and then print out the first six rows of the data frame.
require(coursekata)
# modify this to calculate 1,000 PREs based on shuffled data
sdoPRE <- PRE(shuffle(Tip) ~ Condition, data = TipExperiment)
# print the first 6 lines of sdoPRE
# modify this to calculate 1,000 PREs based on shuffled data
sdoPRE <- do(1000) * PRE(shuffle(Tip) ~ Condition, data = TipExperiment)
# print the first 6 lines of sdoPRE
head(sdoPRE)
ex() %>% {
check_object(., "sdoPRE") %>%
check_equal()
check_function(., "head") %>%
check_result() %>%
check_equal()
} PRE
1 0.002577500
2 0.013398877
3 0.043751521
4 0.021976798
5 0.003006396
6 0.014355646Examining the Sampling Distribution of PRE
The process we used to create the sampling distribution of PREs is similar to the one we used in the prior chapter to create a sampling distribution of \(b_1\)s. In both cases we used the shuffle() function to simulate the empty model of the DGP.
Does the sampling distribution of PRE look similar to the sampling distribution of \(b_1\)? Let’s find out! Use the code window below to make a histogram of the randomly generated PREs in the sdoPRE data frame.
require(coursekata)
sdoPRE <- do(1000) * PRE(shuffle(Tip) ~ Condition, data = TipExperiment)
# make a histogram of the variable PRE (in the data frame sdoPRE)
sdoPRE <- do(1000) * PRE(shuffle(Tip) ~ Condition, data = TipExperiment)
# make a histogram of the variable PRE (in the data frame sdoPRE)
gf_histogram(~ PRE, data = sdoPRE)
ex() %>% check_or(
check_function(., "gf_histogram") %>% {
check_arg(., "object") %>% check_equal()
check_arg(., "data") %>% check_equal(eval = FALSE)
},
override_solution(., '{
sdoPRE <- do(1000) * PRE(shuffle(Tip) ~ Condition, data = TipExperiment)
gf_histogram(sdoPRE, ~ PRE)
}') %>%
check_function("gf_histogram") %>% {
check_arg(., "object") %>% check_equal(eval = FALSE)
check_arg(., "gformula") %>% check_equal()
},
override_solution(., '{
sdoPRE <- do(1000) * PRE(shuffle(Tip) ~ Condition, data = TipExperiment)
gf_histogram(~sdoPRE$PRE)
}') %>%
check_function("gf_histogram") %>%
check_arg("object") %>%
check_equal()
)
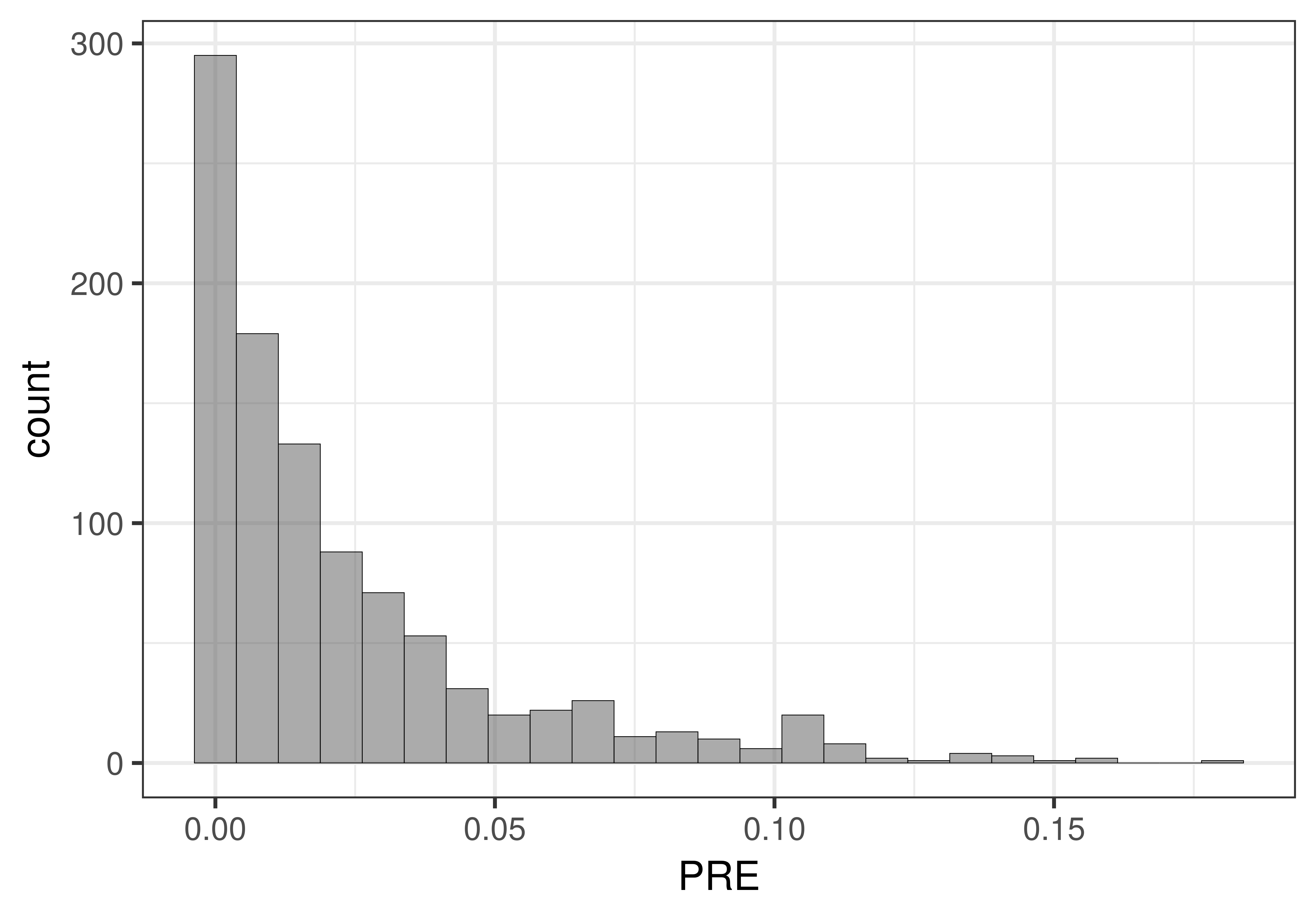
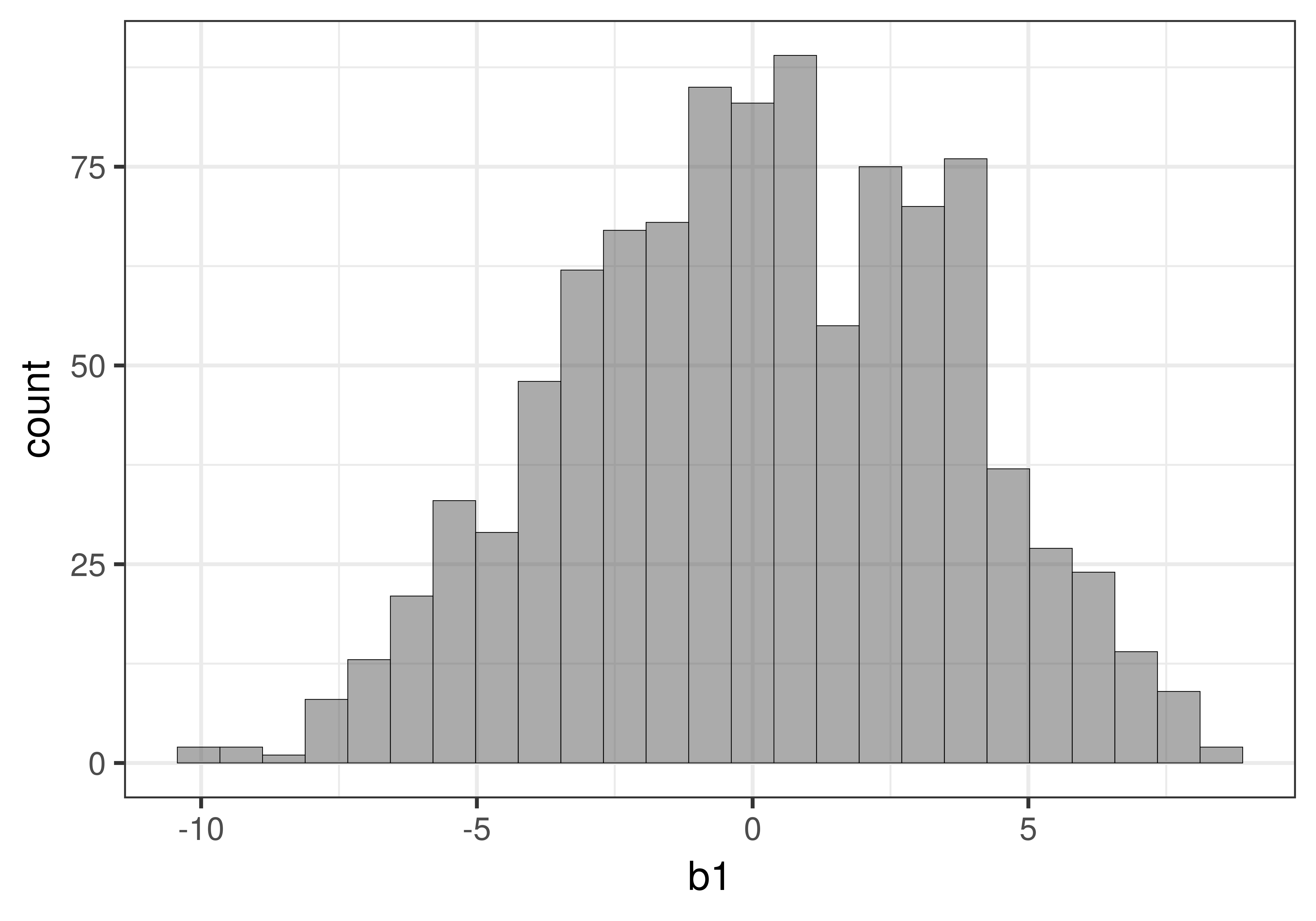
Interestingly, the sampling distribution of PRE has a very different shape than the sampling distribution of \(b_1\). In the figure below we put the two sampling distributions side by side for purposes of comparison.
|
|
|
|---|
The sampling distribution of \(b_1\) has two tails because the difference between the two conditions could be positive or could be negative: Smiley face could have resulted in more tips, or could have resulted in fewer tips. Both are possible (though the researchers no doubt expected it would result in more tips).
But PRE is different: The complex model can explain none of the error from the empty model (0), or all of the error from the empty model (1.0). But it cannot explain less than 0 error. Because PRE is a proportion, it has a clear lower bound of 0, and a clear upper bound of 1.
Assuming the empty model is true, the only place an extreme PRE could fall is in the upper tail of the distribution, which is why there is only one tail. An extreme positive effect of smiley face or an extreme negative effect of smiley face are both the same to PRE: both would fall in the upper tail of the sampling distribution of PRE.
Constructing a Sampling Distribution of F
So far we have constructed and examined the sampling distribution of PRE to examine the variation in PREs that could be generated by the empty model in the context of the tipping experiment. We can use the same method to construct the sampling distribution of F.
In fact, using the sampling distribution of F is one of the most common ways to evaluate the empty model (or do a Null Hypothesis Significance Test, NHST). It is so popular, in fact, that it has its own name: the F-test. For this reason, we will spend a little time investigating the sampling distribution of F.
Just as we have an R function to directly calculate the PRE for a model, we also have one to calculate F: fVal. The following line of code calculates the sample F ratio that results from fitting the Condition model to the tipping study data.
fVal(Tip ~ Condition, data = TipExperiment)3.3049725526482Armed with the fVal() function, we can use the same approach we used for PRE to construct the sampling distribution of F. We will use shuffle() to simulate a DGP in which the only difference between the groups is due to randomization, and then use fVal() to find the F for the shuffled data. We will then repeat this process many times to create the sampling distribution.
Use the code block below to save 1000 randomly generated F ratios in a data frame called sdoF (an acronym for the sampling distribution of F). We’ve already provided some code that will display this distribution in a histogram.
require(coursekata)
# save 1000 randomly generated F ratios in a data frame called sdoF
sdoF <-
gf_histogram(~ fVal, data = sdoF, fill = "darkgoldenrod1")
# save 1000 randomly generated F ratios in a data frame called sdoF
sdoF <- do(1000) * fVal(shuffle(Tip) ~ Condition, data = TipExperiment)
gf_histogram(~ fVal, data = sdoF, fill = "darkgoldenrod1")
ex() %>%
check_object("sdoF") %>%
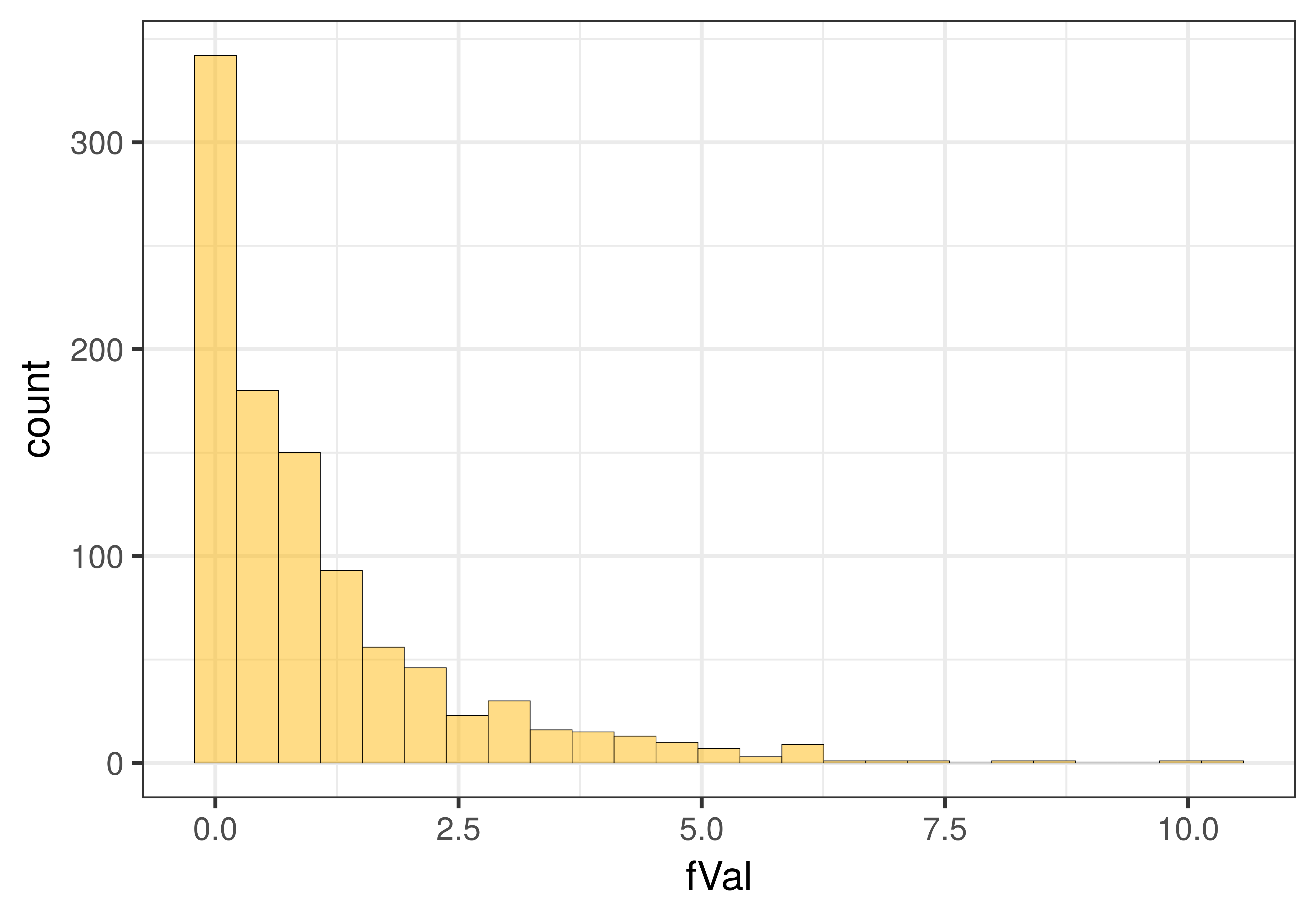
check_equal()Below on the right we have plotted a histogram of the randomized sampling distribution of F. On the left we have plotted the sampling distribution of PRE for purposes of comparison.
|
|
|
|---|
You may be happy to find that the shapes of the sampling distributions of PRE and F are very similar. Neither of these sample statistics can be negative. And, the result of either a large positive or large negative effect of smiley face on Tip would both yield extreme Fs in the upper tail of the distribution.
Both of these sampling distributions are based on the assumption that the empty model is true in the DGP. We have previously developed the idea that if there is no effect of smiley face in the DGP (i.e., the empty model is true) then PRE in the DGP would be equal to 0. This means that knowing which condition a table is in explains literally 0% of the variation in Tip, which is the same as saying \(\beta_1=0\).
But what would the expected value of F be if the empty model were true? F is a more difficult concept to understand, and so we won’t develop this fully here. But if the empty model were true, meaning that PRE were literally 0, then the expected value of F would be 1. The variance estimated using the model predictions would be roughly equal to the variance estimated based on the error within groups.
To confirm that this is true, you can use the code window below to calculate the mean of fVal for our sampling distribution of F. Because our sampling distribution, which we created using shuffle(), assumes that the empty model is true, the average of all the Fs we generated should be roughly equal to 1.
require(coursekata)
# we have created the sdoF for you
sdoF <- do(1000) * fVal(shuffle(Tip) ~ Condition, data = TipExperiment)
# calculate the mean of fVal
favstats( )
# we have created the sdoF for you
sdoF <- do(1000) * fVal(shuffle(Tip) ~ Condition, data = TipExperiment)
# calculate the mean of fVal
favstats(~ fVal, data = sdoF)
ex() %>% {
check_function(., "favstats") %>%
check_result() %>%
check_equal()
}Because the sampling distribution of F is more common and highly similar to the sampling distribution of PRE, we will focus on using the distribution made of Fs. However, just know that everything we say in the next few sections will also apply to PREs.