3.8 Interpreting the Parameter Estimates for a Regression Model
Previously, we used the lm() function to fit the HomeSizeK model of PriceK and saved it as HomeSizeK_model:
HomeSizeK_model` <- lm(PriceK ~ HomeSizeK, data = Ames)Let’s now look at the parameter estimates for this model and see how to interpret them. Use the code block below to print out the parameter estimates for the height model.
We’ve already saved the model as HomeSizeK_model. Print its contents out in the code block below.
library(coursekata)
# saves the home size model
HomeSizeK_model <- lm(PriceK ~ HomeSizeK, data = Ames)
# print it out
# saves the home size model
HomeSizeK_model <- lm(PriceK ~ HomeSizeK, data = Ames)
# print it out
HomeSizeK_model
ex() %>% check_output_expr("HomeSizeK_model")Call:
lm(formula = PriceK ~ HomeSizeK, data = Ames)
Coefficients:
(Intercept) HomeSizeK
24.68 106.60 The Intercept corresponds to \(b_0\) and the HomeSizeK coefficient corresponds to \(b_1\). We can write our fitted model as:
\[\text{PriceK}_i=24.68 + 106.60\text{HomeSizeK}_i+e_i\]
Or, equivalently, using GLM notation, it can be written:
\[Y_i=24.68 + 106.60X_i+e_i\]
\(b_0\), which is 24.68, is the y-intercept. It’s the predicted \(Y_i\) (PriceK) when \(X_i\) (HomeSizeK) equals 0.
Neither a HomeSizeK of 0 square feet nor a sales price of $24,680 are possible. Not all predictions from a regression model make sense. We should always be thinking about which values of the predictors, and which predictions, are reasonable.
How Regression Models Make Predictions
Similar to our use of the Neighborhood model, we can use the HomeSizeK model to predict the price at which a new home will sell. This time, however, we will adjust the prediction based on home size instead of neighborhood.
Recall that price (and predicted price) are in $1000 dollar units. \(b_0\) (24.68 or $24,680) is the predicted price for a home with a size of 0. If we stretch out the x-axis to include 0, we would expect the regression line to cross the y-axis at 24.68. (Notice, however, that in the plot below that there are no actual homes of size 0, for obvious reasons!)

The \(b_1\) estimate (106.60) is the slope: for every 1 unit increase in HomeSizeK, our model predicts a 106.60 increase in PriceK. The fact that HomeSizeK is measured in thousands of square feet and PriceK in thousands of dollars is not a problem; the regression line is a function (the \(b_0 + b_1HomeSizeK\) part) that takes in square feet and then makes a prediction in dollars. This means that homes with 1K more square feet are predicted by our model to have a $106.60K higher price tag (on average). Here’s a visual representation:
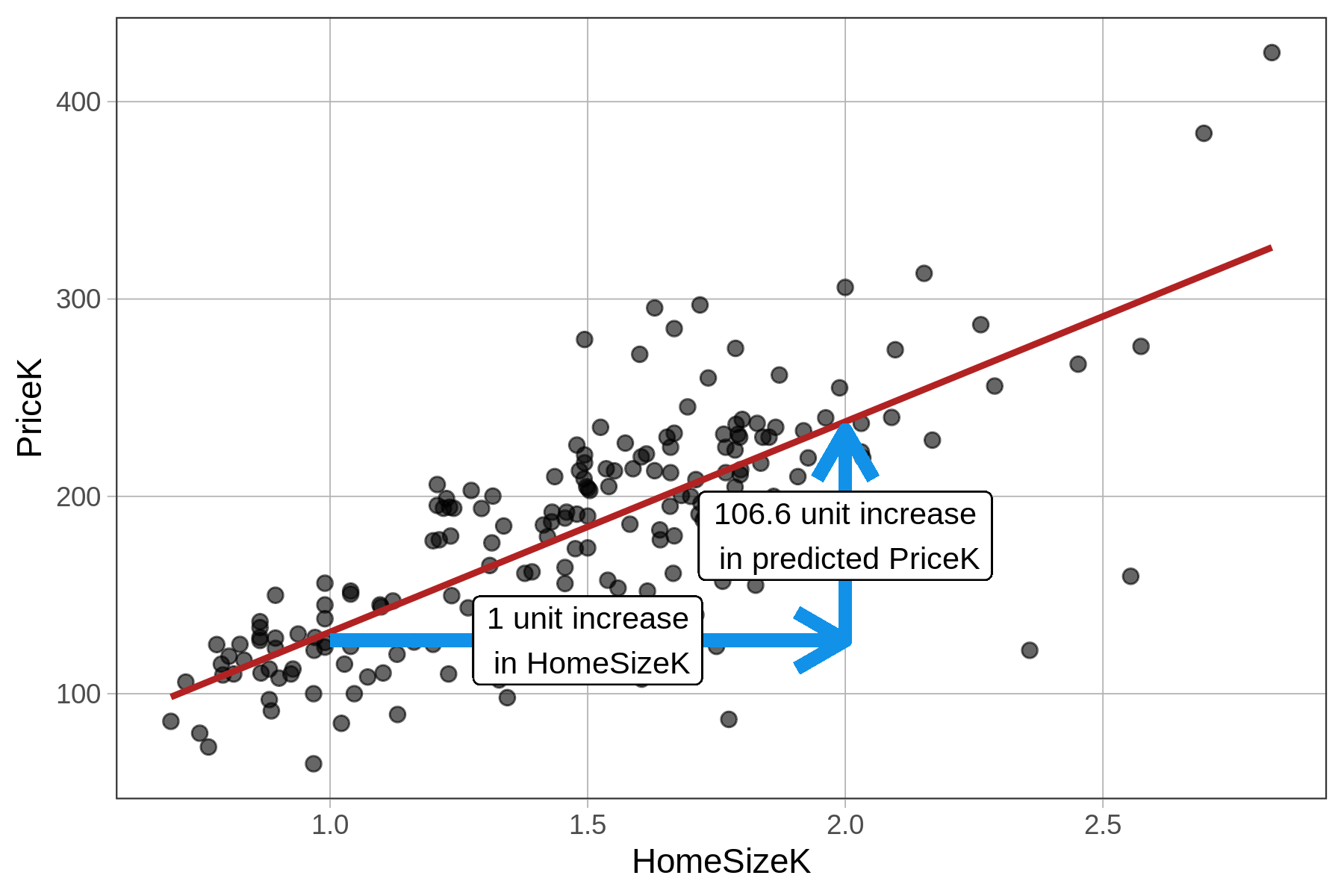
The predicted price of a 2.41K square foot home (that is, 2,410 square feet) is $281.59K. This is the \(Y_i\) (PriceK) on the regression line when \(X_i\) (HomeSizeK) is 2.41, as visualized below:

Comparing the Neighborhood Model and the HomeSizeK Model
Having now specified and fit two models, one a group model and the other a regression model, let’s just think for a bit on what the similarities and differences are between these models.
| Symbol |
Group Mean Model \(\text{Price}_i=b_0+b_1\text{Neighborhood}_i+e_i\) |
Regression Model \(\text{Price}_i=b_0+b_1\text{HomeSize}_i+e_i\) |
|---|---|---|
| \(Y_i\) | Price of home i | Price of home i |
| \(b_0\) |
Predicted home price when \(\text{Neighborhood}_i = 0\) (mean home price in College Creek) |
Predicted home price when \(\text{HomeSizeK}_i=0\) (y-intercept for regression line) |
| \(b_1\) |
Adjustment to predicted price for a home in Old Town (the mean difference between the two group means) |
Adjustment to predicted price for a one-unit increase in home size (the slope of the regression line) |
| \(X_i\) | Neighborhood of home i, coded as 0=not-Old Town, 1=Old Town | Home size of home i in thousands of square feet |
| \(e_i\) | Error for home i | Error for home i |