6.5 Z-Scores
We have looked at the mean as a model; and we have learned some ways to quantify total error around the mean, as well as some good reasons for doing so. But there is another reason to look at both mean and error together. Sometimes, by putting the two ideas together it can give us a better way of understanding where a particular score falls in a distribution.
A student (let’s call her Zelda) has a thumb length of 65.1 mm. What does this mean? Is that a particularly long thumb? How can we know? By now you may be getting the idea that just knowing the length of one thumb doesn’t tell you very much.
To interpret the meaning of a single score, it helps to know something about the distribution the score came from. Specifically, we need to know something about its shape, center and spread.
We know that this student’s thumb is about 5 mm longer than the average. But because we have no idea about the spread of the distribution, we still don’t have a very clear idea of how to judge 65.1 mm thumb length. Is a 5 mm distance still pretty close to the mean, or is it far away? It’s hard to tell without knowing what the range of thumb lengths looks like.
Although SS will be really useful later, for this purpose it stinks. 65.1 and 11,880 don’t seem like they belong in the same universe! Variance will also be useful, but its units are still somewhat hard to interpret. It’s hard to use squared millimeters as a unit when trying to make sense of unsquared millimeters.
Standard deviation, on the other hand, is really useful. We know that Zelda’s thumb is about 5 mm longer than the average thumb. But now we also know that, on average, thumbs are 8.7 mm away from the mean, both above and below. Although Zelda’s thumb is above average in length, it is definitely not one of the longest thumbs in the distribution. Check out the histogram below to see if this interpretation is supported.
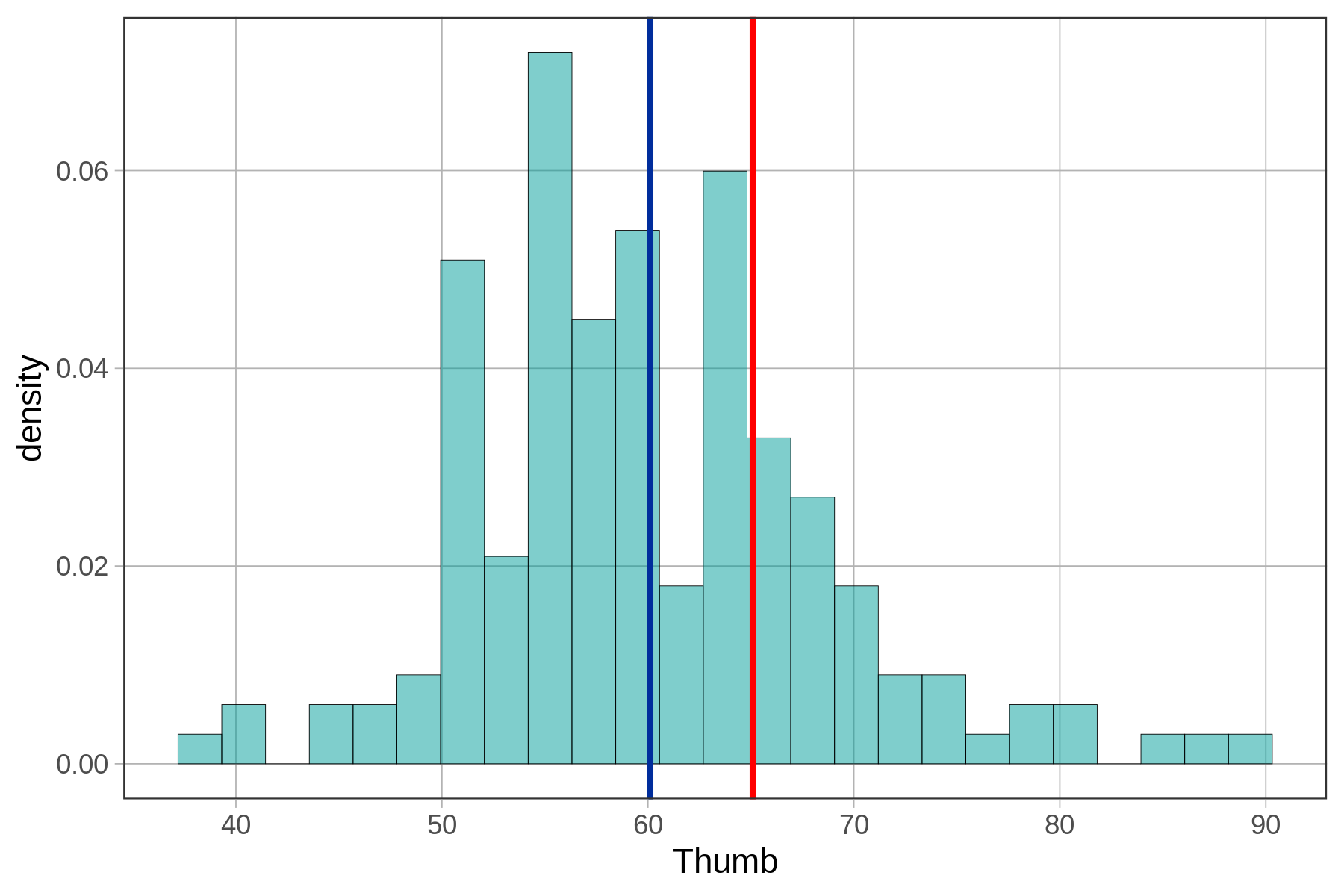
The mean of thumb length is shown in blue, and Zelda’s 65.1 mm thumb is shown in red.
Combining Mean and Standard Deviation
In the Thumb situation, we find it valuable to coordinate both mean and standard deviation in order to interpret the meaning of an individual score. Now, let’s introduce a measure that will combine these two pieces of information into a single score: the z-score.
Let’s say you know that the mean score across all players of the game is 35,000. How would that help you? Clearly it would help. You would know that the score of 37,000 is above the average by 2,000 points. But even though it helps you interpret the meaning of the 37,000, it’s not enough. What it doesn’t tell you is how far above the average 37,000 points is in relation to the whole distribution.
Let’s say the distribution of scores on Kargle is represented by one of these histograms. Both distributions have an average score of 35,000. But in the distribution on the top (#1), the standard deviation is 1,000 points, while on the bottom (#2) the standard deviation is 5,000 points. The blue line depicts the mean, and the red line depicts our friend’s score of 37,000.
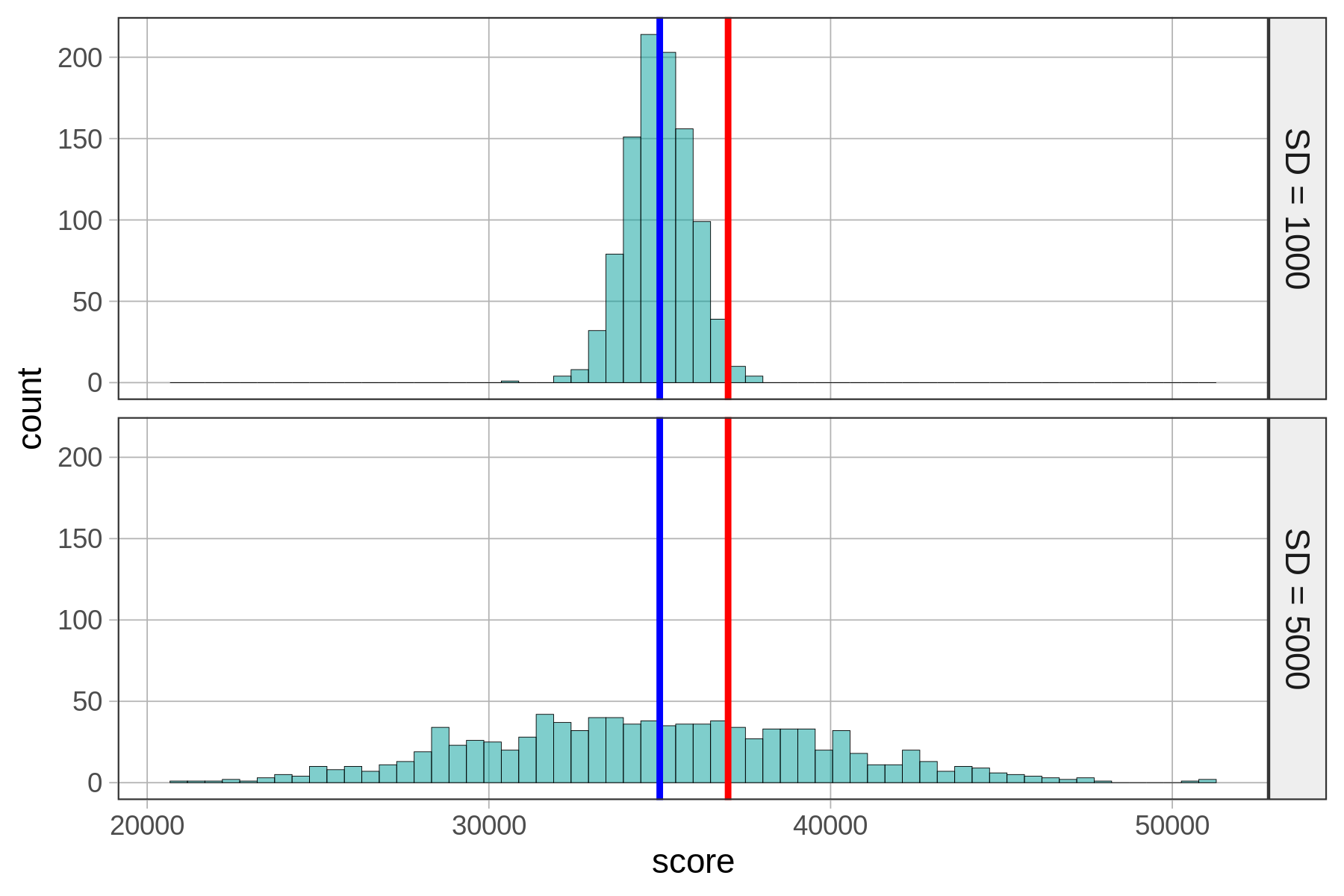
Clearly your friend would be an outstanding player if Distribution 1 were true. But if Distribution 2 were true, they would be just slightly above average.
We can see this visually just by looking at the two histograms. But is there a way to quantify this intuition? One way to do this is by transforming the score we are trying to interpret into a z-score using this formula:
\[z_i=\frac{Y_i-\bar{Y}}{s}\]
Let’s apply this formula to our video game score of 37,000 based on each of the two hypothetical distributions (#1 and #2) above.
We show you the R code for calculating the z-score for a score of 37,000 if Distribution 1 is true. Write similar code to calculate z-score if Distribution 2 is true.
require(coursekata)
# z-score if distribution 1 were true
(37000 - 35000)/1000
# z-score if distribution 2 were true
(37000 - 35000)/1000
(37000 - 35000)/5000
ex() %>% {
check_output_expr(., "(37000 - 35000)/1000")
check_output_expr(., "(37000 - 35000)/5000", missing_msg="Did you divide by the sd of the second distribution?")
}20.4In both cases, the numerator is the same: 37,000 (the individual score) minus the mean of the distribution, which equals 2,000. The denominators for the two z-scores are different, though, because the distributions have different standard deviations. In distribution #1, the standard deviation is 1,000. So, the z-score is 2,000 divided by 1,000, or 2. For the other distribution, the standard deviation is 5,000. So, the z-score is 2,000 divided by 5,000, or .40.
If we did this calculation without parentheses, the calculation would be 37,000 - (35,000 / 5,000) because order of operations, our cultural conventions for how we do arithmetic, says that division is done before subtraction.
A z-score represents the number of standard deviations a score is above (if positive) or below (if negative) the mean. So, the units are standard deviations. A z-score of 2 is two standard deviations above the mean. A z-score of 0.4 is 0.4 standard deviations above the mean.
A z-score of 2 is more impressive—it’s two standard deviations above the mean. It should be harder to score two standard deviations above the mean than to score 0.4 (or less than one half) a standard deviation above the mean.