3.6 The Back and Forth Between Data and the DGP (Continued)
Examining Variation Across Samples
Let’s take a simulated sample of 12 die rolls (sampling with replacement from the six possible outcomes) and save it in a vector called sample1.
Add some code to create a density histogram (which could also be called a relative frequency histogram) to examine the distribution of our sample. Set bins=6.
require(coursekata)
set.seed(4)
model_pop <- 1:6
sample1 <- resample(model_pop, 12)
# Write code to create a relative frequency histogram
# Remember to put in bins as an argument
# Don't use any custom coloring
model_pop <- 1:6
sample1 <- resample(model_pop, 12)
# you have to uncomment this line for it to work
# gf_dhistogram(~ sample1, bins = 6)
ex() %>% {
override_solution_code(.,
'model_pop <- 1:6; sample1 <- resample(model_pop, 12); gf_dhistogram(~ sample1, bins = 6)'
) %>% {
check_object(., "sample1") %>% check_equal()
check_function(., "gf_dhistogram") %>% {
check_arg(., "bins")
check_arg(., "object") %>% check_equal(eval = FALSE)
}
}
}Your random sample will look different from ours (after all, random samples differ from one another) but here is one of the random samples we generated.
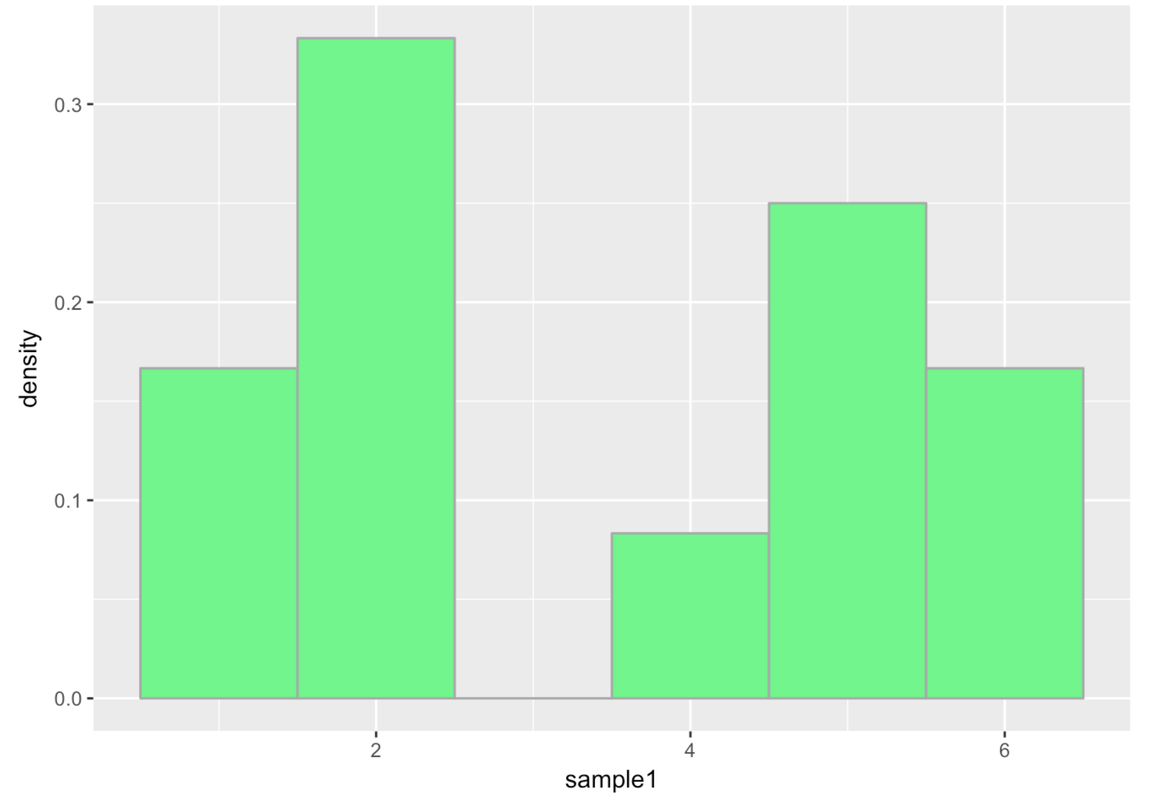
(Just a reminder–our histograms may look different because we might fancy up our histograms with colors and labels and things. Sometimes we may ask you to refrain from doing so because it makes it harder for R to check your answer.) Notice that this doesn’t look very much like the uniform distribution we would expect based on our knowledge of the DGP!
Let’s take a larger sample—24 die rolls. Modify the code below to simulate 24 die rolls, save it as a vector called sample2. Will the distribution of this sample be perfectly uniform?
require(coursekata)
set.seed(5)
model_pop <- 1:6
# Modify this code from 12 dice rolls to 24 dice rolls
sample2 <- resample(model_pop, 12)
# This will create a density histogram
gf_dhistogram(~ sample2, color = "darkgray", fill = "springgreen", bins = 6)
model_pop <- 1:6
# Modify this code from 12 dice rolls to 24 dice rolls
sample2 <- resample(model_pop, 24)
# This will create a density histogram (you have to uncomment the line for it to work)
# gf_dhistogram(~ sample2, color = "darkgray", fill = "springgreen", bins = 6)
ex() %>% check_object("sample2") %>% check_equal()
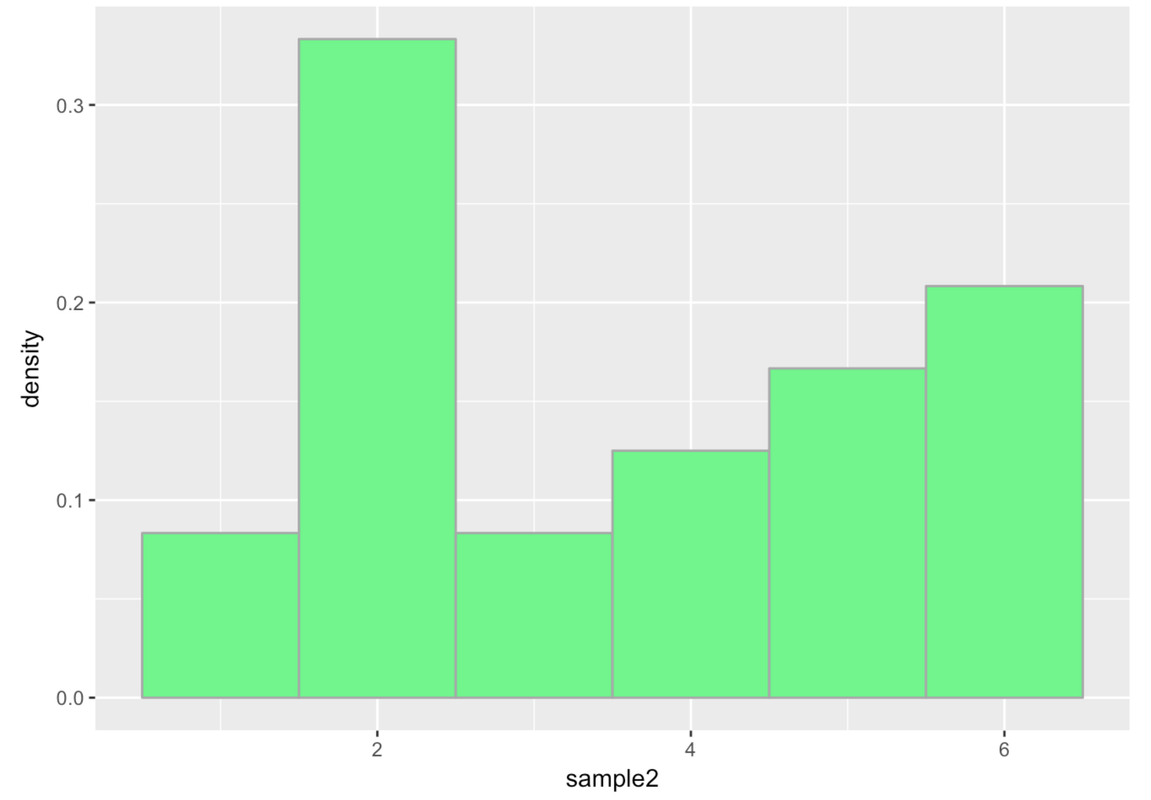
Notice that our randomly generated sample distribution is also not perfectly uniform. In fact, this doesn’t look very uniform to our eyes at all! You might even be asking yourself, is this really a random process?
Simulate a few more samples of 24 die rolls (we will call them sample3, sample4, and sample5) and plot them on histograms. This time, add a density plot on top of your histograms (using gf_density()). Do any of these look exactly uniform?
require(coursekata)
set.seed(7)
model_pop <- 1:6
# create samples #3, #4, #5 of 24 dice rolls
sample3 <-
sample4 <-
sample5 <-
# this will create a density histogram of your sample3
# add onto it to include a density plot
gf_dhistogram(~ sample3, color = "darkgray", fill = "springgreen", bins = 6)
# create density histograms of sample4 and sample5 with density plots
model_pop <- 1:6
# create samples
sample3 <- resample(model_pop, 24)
sample4 <- resample(model_pop, 24)
sample5 <- resample(model_pop, 24)
# this will create a density histogram of your sample3
# add onto it to include a density plot
# gf_dhistogram(~ sample3, color = "darkgray", fill = "springgreen", bins = 6) %>%
# gf_density()
# create density histograms of sample4 and sample5 with density plots
# gf_dhistogram(~ sample4, color = "darkgray", fill = "springgreen", bins = 6) %>%
# gf_density()
# gf_dhistogram(~ sample5, color = "darkgray", fill = "springgreen", bins = 6) %>%
# gf_density()
ex() %>% override_solution_code('{
model_pop <- 1:6
sample3 <- resample(model_pop, 24)
sample4 <- resample(model_pop, 24)
sample5 <- resample(model_pop, 24)
gf_dhistogram(~ sample3, color = "darkgray", fill = "springgreen", bins = 6) %>%
gf_density()
gf_dhistogram(~ sample4, color = "darkgray", fill = "springgreen", bins = 6) %>%
gf_density()
gf_dhistogram(~ sample5, color = "darkgray", fill = "springgreen", bins = 6) %>%
gf_density();
}') %>%
{
check_object(., "sample3") %>% check_equal()
check_object(., "sample4") %>% check_equal()
check_object(., "sample5") %>% check_equal()
check_function(., "gf_dhistogram", index = 1) %>%
check_arg("object") %>% check_equal(eval = FALSE)
check_function(., "gf_dhistogram", index = 2) %>%
check_arg("object") %>% check_equal(eval = FALSE)
check_function(., "gf_dhistogram", index = 3) %>%
check_arg("object") %>% check_equal(eval = FALSE)
check_function(., "gf_density", index = 1)
check_function(., "gf_density", index = 2)
check_function(., "gf_density", index = 3)
}
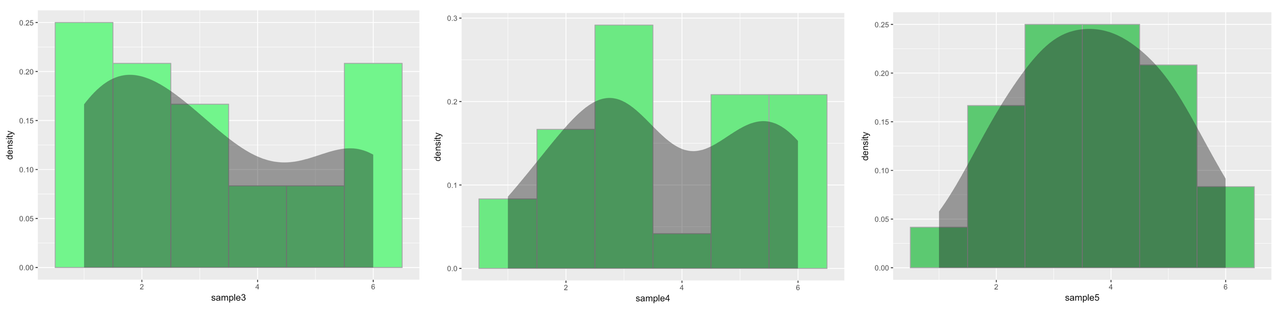
Wow, these look crazy and they certainly do not look uniform. They also don’t even look similar to each other. What is going on here?
The fact is, these samples were, indeed, generated by a random process: simulated die rolls. And we assure you, at least here, there is no error in the programming. The important point to understand is that sample distributions can vary, even a lot, from the underlying population distribution from which they are drawn. This is what we call sampling variation. Small samples will not necessarily look like the population they are drawn from, even if they are randomly drawn.
Large Samples Versus Small Samples
Even though small samples will often look really different from the population they were drawn from, larger samples usually will not.
For example, if we ramped up the number of die rolls to 1,000, we will see a more uniform distribution. Complete then run the code below to see.
require(coursekata)
set.seed(7)
model_pop <- 1:6
# create a sample with 1000 rolls of a die
large_sample <-
# this will create a density histogram of your large_sample
gf_dhistogram(~ large_sample, color = "darkgray", fill = "springgreen", bins = 6)
model_pop <- 1:6
# create a sample with 1000 rolls of a die
large_sample <- resample(model_pop, 1000)
# this will create a density histogram of your large_sample
# gf_dhistogram(~ large_sample, color = "darkgray", fill = "springgreen", bins = 6)
ex() %>% override_solution_code('{
model_pop <- 1:6
# create a sample with 1000 rolls of a die
large_sample <- resample(model_pop, 1000)
# this will create a density histogram of your largesample
gf_dhistogram(~ large_sample, color="darkgray", fill="springgreen", bins=6)
}') %>% {
check_object(., "large_sample") %>% check_equal()
check_function(., "gf_dhistogram") %>%
check_arg("object") %>%
check_equal(eval = FALSE)
}
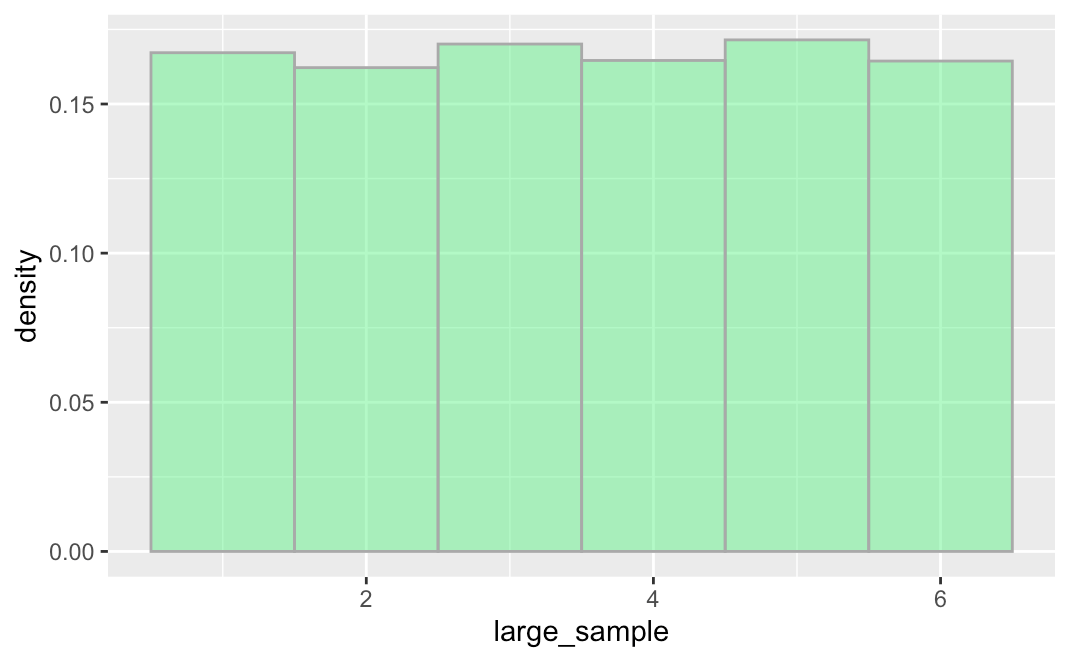
Wow, a large sample looks a lot more like what we expect the distribution of die rolls to look like! This is also why we make a distinction between the DGP and the population. When you run a DGP (such as resampling from the numbers 1 to 6) for a long time (like 10,000 times), you end up with a distribution that we can start to call a population.
Even though small samples are unreliable and sometimes misleading, large samples usually tend to look like the parent population that they were drawn from. This is true even when you have a weird population. For example, we made up a simulated population that kind of has a “W” shape. We put it in a vector called w_pop. Here’s a density histogram of the population.
gf_dhistogram(~ w_pop, color = "black", bins = 6)
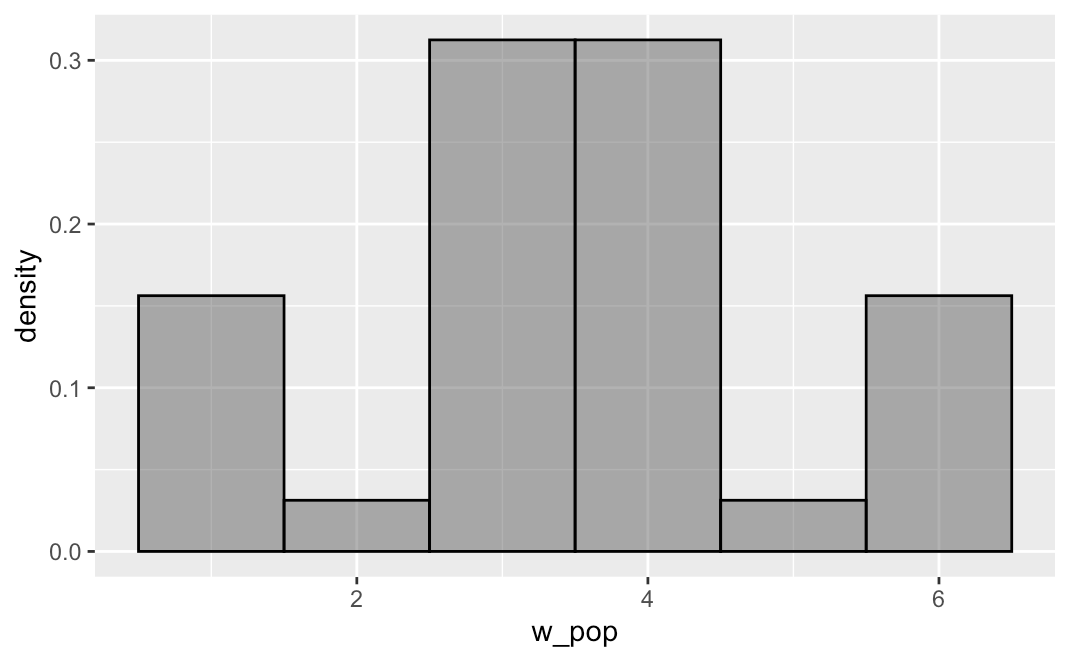
Now try drawing a relatively small sample (n = 24) from w_pop (with replacement) and save it as small_sample. Let’s observe whether the small sample looks like this weird W-shape.
require(coursekata)
set.seed(10)
model_pop <- 1:6
w_pop <- c(rep(1,5), 2, rep(3,10), rep(4,10), 5, rep(6,5))
# Create a sample that draws 24 times from w_pop
small_sample <-
# This will create a density histogram of your small_sample
gf_dhistogram(~ small_sample, color = "darkgray", fill = "mistyrose", bins = 6)
# Create a sample that draws 24 times from w_pop
small_sample <- resample(w_pop, 24)
# This will create a density histogram of your small_sample
# gf_dhistogram(~ small_sample, color = "darkgray", fill = "mistyrose", bins = 6)
ex() %>% override_solution_code('{
# Create a sample that draws 24 times from w_pop
small_sample <- resample(w_pop, 24)
# This will create a density histogram of your small_sample
gf_dhistogram(~ small_sample, color = "darkgray", fill = "mistyrose", bins = 6)
}') %>% {
check_object(., "small_sample") %>% check_equal()
check_function(., "gf_dhistogram") %>%
check_arg("object") %>%
check_equal()
}
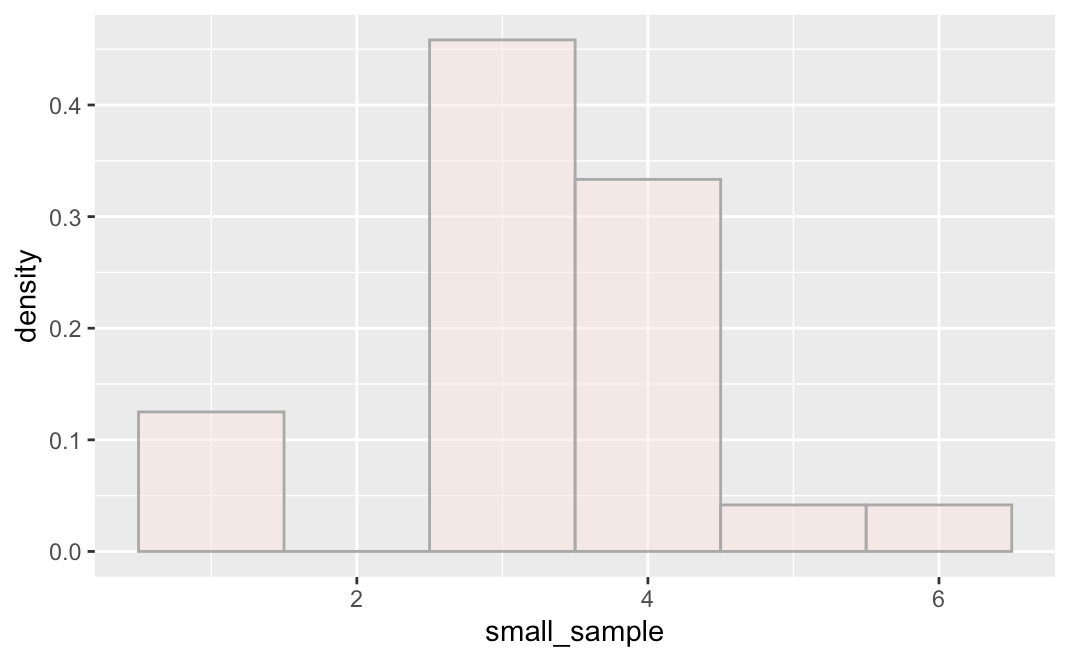
Now try drawing a large sample (n = 1,000) and save it as large_sample. Will this one look more like the weird population it came from than the small sample?
require(coursekata)
set.seed(7)
model_pop <- 1:6
w_pop <- c(rep(1,5), 2, rep(3,10), rep(4,10), 5, rep(6,5))
# create a sample that draws 1000 times from w_pop
large_sample <-
# this will create a density histogram of your large_sample
gf_dhistogram(~ large_sample, color = "darkgray", fill = "mistyrose", bins = 6)
# create a sample that draws 1000 times from w_pop
large_sample <- resample(w_pop, 1000)
# this will create a density histogram of your large_sample
# gf_dhistogram(~ large_sample, color = "darkgray", fill = "mistyrose", bins = 6)
ex() %>% override_solution_code('{
# create a sample that draws 1000 times from w_pop
large_sample <- resample(w_pop, 1000)
# this will create a density histogram of your large_sample
gf_dhistogram(~ large_sample, color = "darkgray", fill = "mistyrose", bins = 6)
}') %>% {
check_object(., "large_sample") %>% check_equal()
check_function(., "gf_dhistogram") %>%
check_arg("object") %>%
check_equal()
}
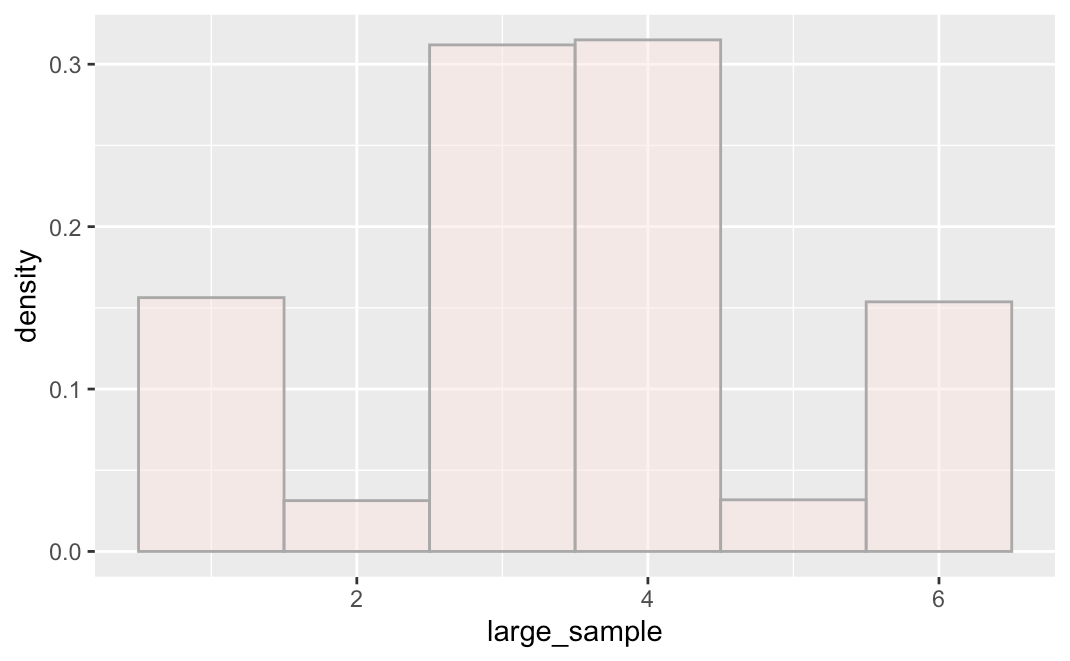
That looks very close to the W-shape of the simulated population we started off with.
This pattern that large samples tend to look like the populations they came from is so reliable in statistics that it is referred to as a law: the law of large numbers. This law says that, in the long run, by either collecting lots of data or doing a study many times, we will get closer to understanding the true population and DGP.
Lessons Learned
In the case of dice rolls (or even in the weird W-shaped population), we know what the true DGP looks like because we made it up ourselves. Then we generated random samples. What we learned is that smaller samples will vary, with very few of them looking exactly like the process that we know generated them. But a very large sample will look more like the population.
In fact, it is unusual in real research to know what the true DGP looks like. Also we rarely have the opportunity to collect truly large samples! In the typical case, we only have access to relatively small sample distributions, and usually only one sample distribution. The realities of sampling variation, which you have now seen up close, make our job very challenging. It means we cannot just look at a sample distribution and infer, with confidence, what the parent population and DGP look like.
On the other hand, if we think we have a good guess as to what the DGP looks like, we shouldn’t be too quick to give up our theory just because the sample distribution doesn’t appear to support it. In the case of die rolls, this is easy advice to take: even if something really unlikely happens in a sample—e.g., 24 die rolls in a row all come up 5—we will probably stick with our theory! After all, a 5 coming up 24 times in a row is still possible to occur by random chance, although very unlikely.
But when we are dealing with real-life variables, variables for which the true DGP is fuzzy and unknown, it is more difficult to know if we should dismiss a sample as mere sampling variation just because the sample is not consistent with our theory. In these cases, it is important that we have a way to look at our sample distribution and ask: how reasonable is it to assume that our data could have been generated by our current theory of the DGP?
Simulations can be really helpful in this regard. By looking at what a variety of random samples look like, we can get a sense as to whether our particular sample looks like natural variation, or if, instead, it sticks out as wildly different. If the latter, we may need to revise our understanding of the DGP.