8.6 Modeling the DGP
We have learned how to fit a two-group and a three-group model to data and to see how much error we can reduce with a group model compared to the empty model. We have also learned about quantifying that effect with various measures of effect size (e.g., \(b_1\), PRE, Cohen’s d). But let’s pause for a moment to remember that our main interest is not in a particular data set, but in the Data Generating Process – that is, the process that generated the data.
Considering the DGP of Tips
In the graph below we can see that the tables in the smiley face condition tipped more, on average, than those in the control condition. But we also can see a great deal of overlap between the two distributions. It’s possible that drawing the smiley face on the check caused tables to tip a bit more. But it’s also possible that the effect in the data is just the result of random sampling variation.
Condition_model <- lm(Tip ~ Condition, data = TipExperiment)
gf_jitter(Tip ~ Condition, data = TipExperiment, width = .1) %>%
gf_model(Condition_model)
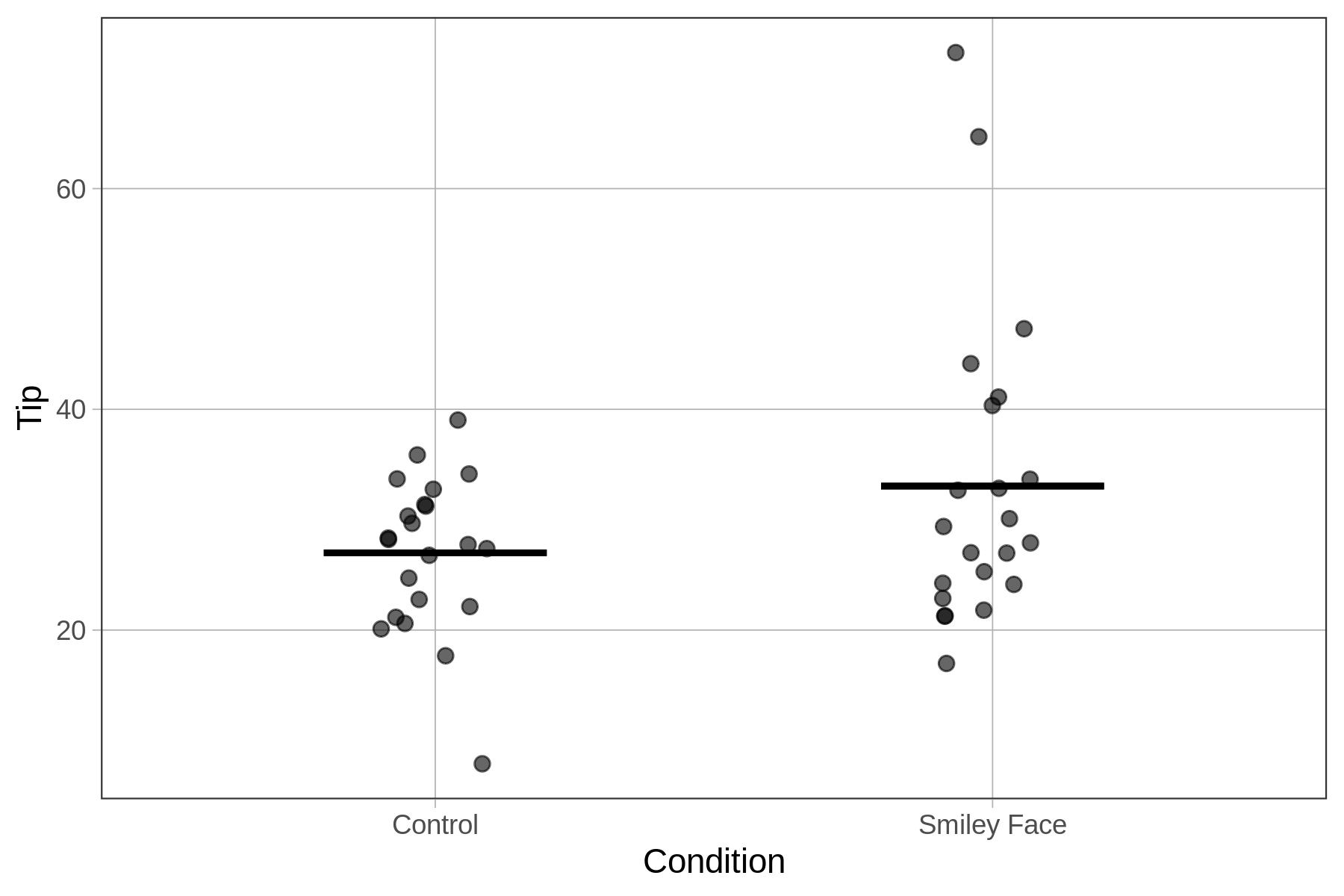
Back in Chapter 4 we considered this possibility by using the shuffle() function to see what patterns of results might result if the true effect of condition in the DGP is purely random. Our approach back then was to graph various re-shuffles of the data, and look to see if the graph of real data looked different from the graphs we generated randomly. Now that we have learned how to fit a two-group model, we will revisit the shuffle() function.
As we will see, the concepts and procedures of statistical modeling that we have learned since then can help us use the shuffle() function in a more sophisticated way. First, it will put the question being asked into a model comparison framework. Second, it will give us a way to quantify our analysis of the randomly-generated data.
Model the Data
Let’s start by looking again at the two-group model of Tip by Condition:
\[\text{Tip}_i=b_0+b_1\text{Condition}_i+e_i\]
When we fit the model using lm() we get the following parameter estimates:
Call:
lm(formula = Tip ~ Condition, data = TipExperiment)
Coefficients:
(Intercept) ConditionSmiley Face
27.000 6.045We’ve plotted the tips broken down by condition, overlaid the predictions of the two-group model, and labeled the \(b_1\) estimate in the figure below. The \(b_1\) estimate shows us that in our data, putting a smiley face on the check results in an increase in tips, on average, of 6 percentage points.
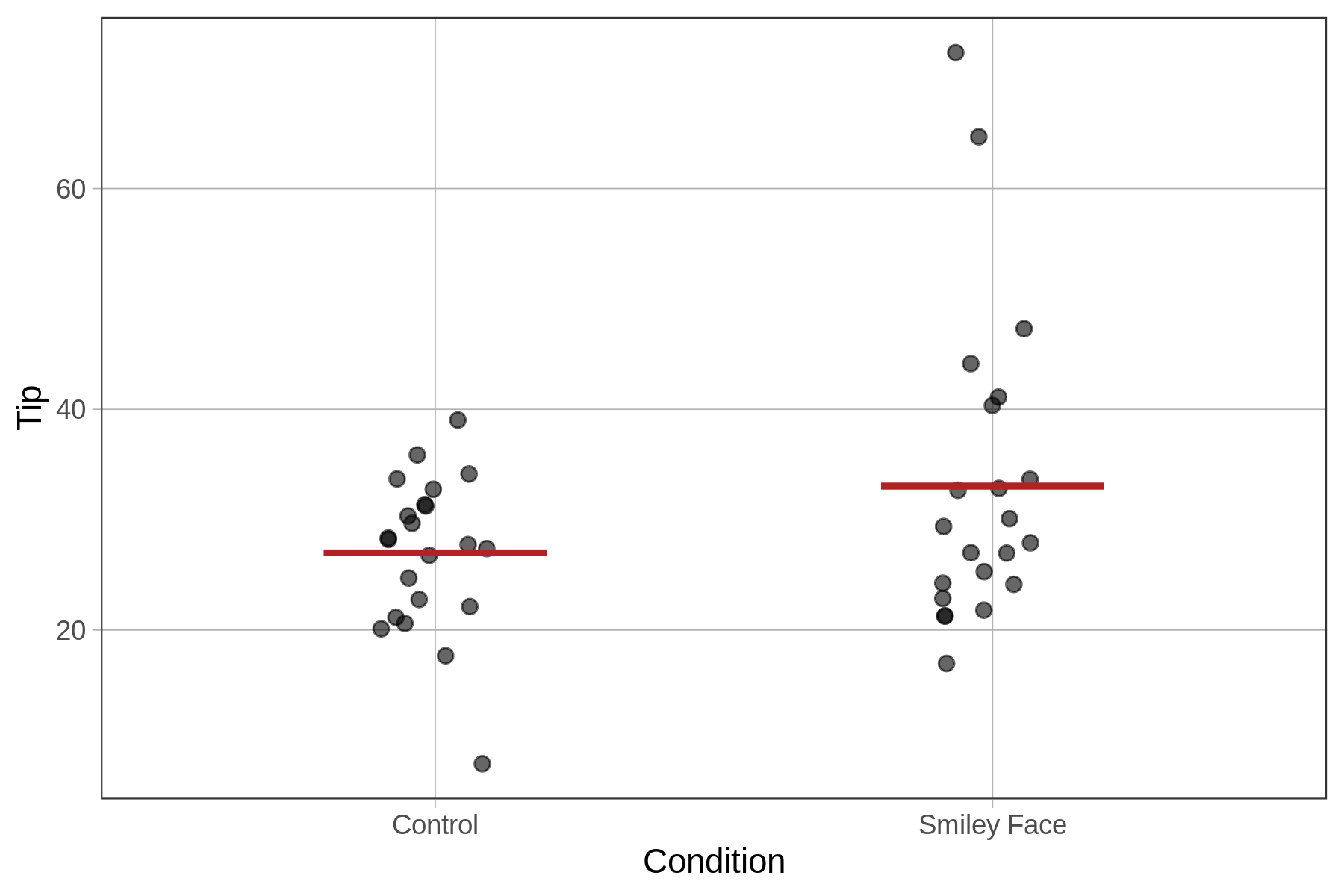
Comparing Two Models of the DGP
Having fit the model, we can return to the same question we posed in Chapter 4, but this time we can pose it in a more sophisticated way. In Chapter 4 we asked: is it possible that the slight increase in tips between the control and smiley face groups was due simply to random sampling variation and not to a true effect in the DGP?
Even though the best-fitting model of the data produces a \(b_1\) estimate of 6 percentage points, is it possible that such an effect could have been produced by a DGP in which \(\beta_1\) is equal to 0?
In other words, based on the data, which model will we adopt? The more complex condition model, in which we estimate the value of \(\beta_1\) to be 6? Or the simpler, empty model, in which \(\beta_1\) is 0?
Condition model: \(\text{Tip}_i=\beta_0+\beta_1\text{Condition}_i+\epsilon_i\)
Empty model: \(\text{Tip}_i=\beta_0+\epsilon_i\)
Note that the only difference between these two models is that the term \(\beta_1Condition_i\) has been deleted from the empty model. If \(\beta_1\) is 0, then this term will drop out of the model.