8.4 Examining Residuals From the Model
Now you’re on a roll! You probably remember from the previous chapter how to save the residuals from a model. We can do the same thing with a regression model: whenever we fit a model, we can generate both predictions and residuals from the model.
Try to generate the residuals from the Height_model that you fit to the full Fingers data set.
require(coursekata)
Fingers <- filter(Fingers, Thumb >= 33 & Thumb <= 100)
Height_model <- lm(Thumb ~ Height, data = Fingers)
# modify to save the residuals from Height_model
Fingers$Height_resid <- resid()
# modify to save the residuals from Height_model
Fingers$Height_resid <- resid(Height_model)
ex() %>% check_object("Fingers") %>% check_column("Height_resid") %>% check_equal()require(coursekata)
Fingers <- filter(Fingers, Thumb >= 33 & Thumb <= 100)
Height_model <- lm(Thumb ~ Height, data = Fingers)
Fingers$Height_resid <- resid(Height_model)
# modify to make a histogram of Height_resid
gf_histogram()
gf_histogram(~Height_resid, data = Fingers)
ex() %>% {
check_function(., "gf_histogram") %>%
check_arg("object") %>%
check_equal(incorrect_msg = "Did you remember to use ~Height_resid in the first argument?")
check_function(., "gf_histogram") %>%
check_arg("data") %>%
check_equal(incorrect_msg = "Make sure to set data = Fingers")
}
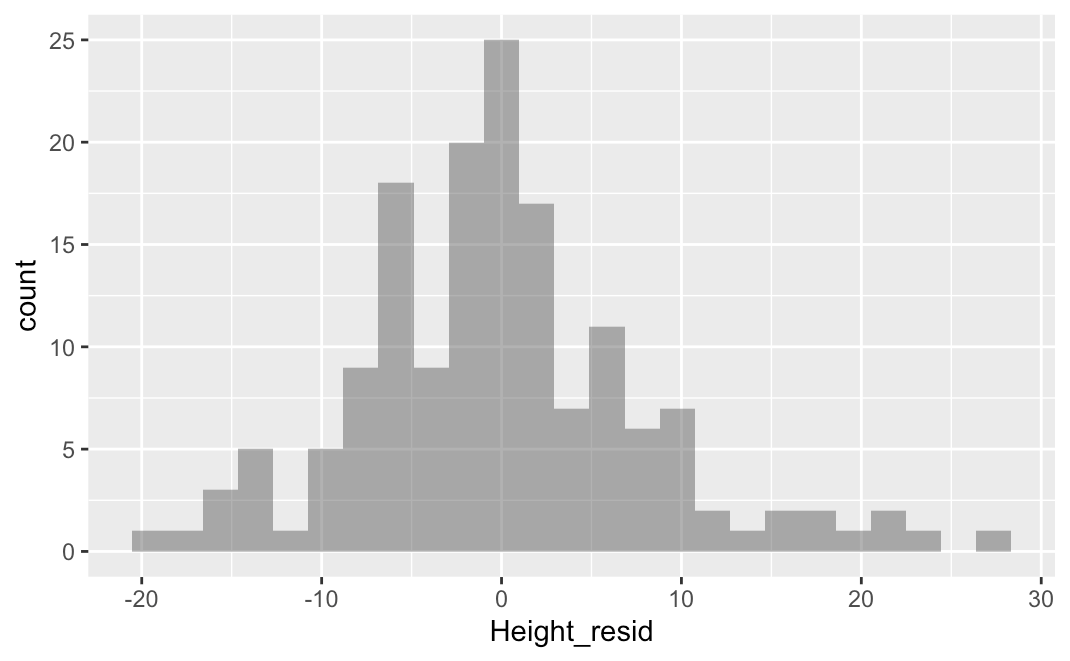
The residuals from the regression line are centered at 0, just as they were from the empty model, the two-group model, and the three-group model. In those previous models, this was true by definition: deviations of scores around the mean will always sum to 0 because the mean is the balancing point of the residuals. Thus the sum of these negative and positive residuals will be 0.
It turns out this is also true of the best-fitting regression line: the sum of the residuals from each score to the regression line add up to 0, by definition. In this sense, too, the regression line is similar to the mean of a distribution in that it perfectly balances the scores above and below the line.